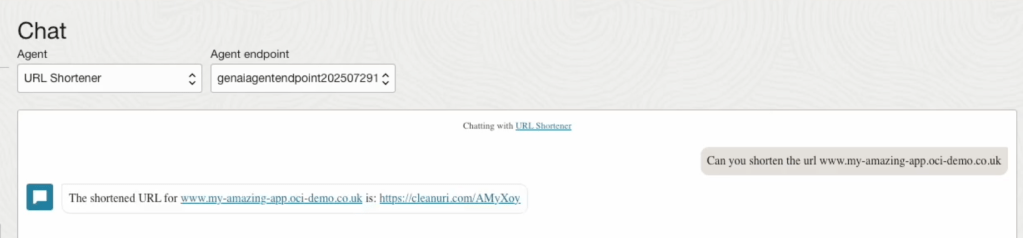
In this short video, I step through how to create an Oracle Generative AI Agent and then configure a tool within the Agent to connect to a public API that performs URL shortening. This uses the new (as of July 2025) API Endpoint Calling Tool functionality within the Generative AI Agents Service.
This allows users to ask the agent to shorten a URL, the agent then calls a public API that can shorten URLs (https://cleanuri.com/docs) and returns a shortened URL to the user.
The Generative AI Agent service in OCI recently added the ability to add a SQL Tool, this enables an agent to generate a SQL query and optionally run the query against a database and return the results of the query to the agent 🤖. I created a short video that steps through how to use a SQL Tool ⚒️ with an agent, which can be found here 📼.
More recently (mid-July 2025) the SQL Tool has been further enhanced so that responses include the following:
The raw output of the SQL query
A conversational “LLM style” response
Previously a SQL Tool would only return the raw output of the SQL query, I found this quite useful as I could use Python packages such as matplotlib to visualise results, as of mid-July responses from the agent also include an LLM style conversational response, for example (taken from my agent that queries a database of bird sightings 🦅):
Raw Output of SQL Query
Conversational LLM Style Response
I’ve put together a short Python script that demonstrates how to get access to this data from a response, I typically use Streamlit as a front-end for the demo agents that I build, however to keep things simple, we’ll use the good old “shell” for this demo!
To use this script you’ll need to update the following:
textinput – update this to reflect the question to ask your agent, unless your agent is knowledgeable on bird sightings 🤣, this will need to update this
service_ep – this is the service endpoint, of which there is a different endpoint for each OCI region – if your agent resides in the UK South region, you don’t need to change this 😀
Finally make sure you have the latest version of the OCI SDK for Python, to upgrade to the latest version run the following command –
pip3 install oci --upgrade
When run the output should look something like this:
Here is an example of how I’ve used matplotlib (within a Streamlit front-end) to visualise results using the raw output of the SQL query.
As you can see below, it returns the conversational response, I then take the raw SQL output and use matplotlib to make it look pretty 💄 – I may put together a post on this too.
This short video (a whole 4 mins! ⏱️) explains the value of using OCI Security Zones and steps through the process of creating a Security Zone that blocks creation of public Object Storage Buckets.
I often use Streamlit to create quick customer demo’s and PoCs for OCI Generative AI Agents. One thing that is really useful is the ability to run a Streamlit app within a container instance rather than locally on my laptop – which is ideal when I need to quickly give others access to the apps that I have built.
Here is a quick guide as to how to take a Streamlit app and run this within an OCI Container Instance 📋.
Step 1 – Ensure Container Instances have access to the Gen AI Agent service and Container Registry ✅
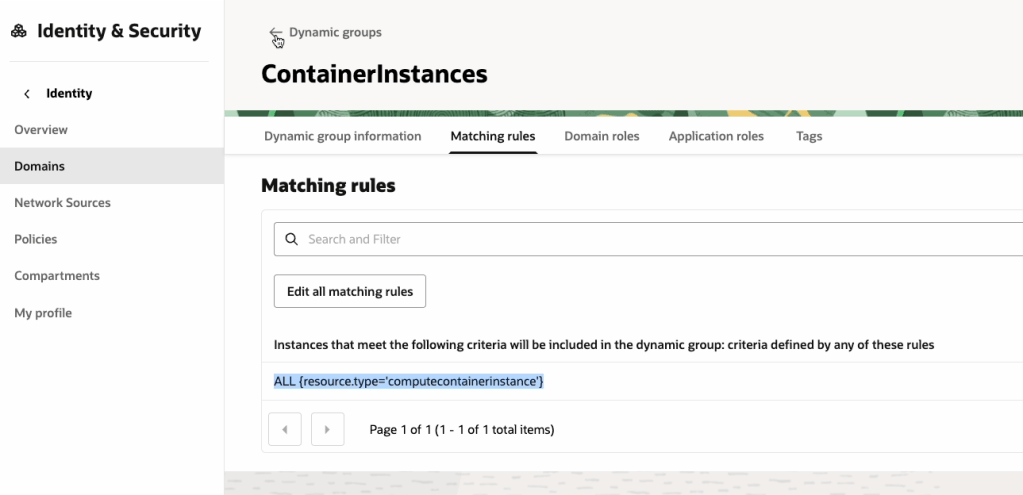
To do this we will need to create a Dynamic Group within OCI IAM, with the following rule:
ALL {resource.type='computecontainerinstance'}
This rule will ensure that every Container Instance within the tenancy is added to the Dynamic Group, which in this example is named “ContainerInstances” – how original! In the real-world, you may want to be more specific and specify a single container instance or Compartment as a member of the Dynamic Group.
Now that the Dynamic Group has been created, we need to create a Policy that provides this group (e.g. all container instances within the tenancy) access to pull images from the OCI Container Registry and also grant it access to the OCI Generative AI Agents service, the reason for the latter is that we will use Resource Principal authentication to authenticate the container instance to the service, rather than the API Keys for a specific user account (which is safer as we won’t need to include any keys within the container image! 🔑).
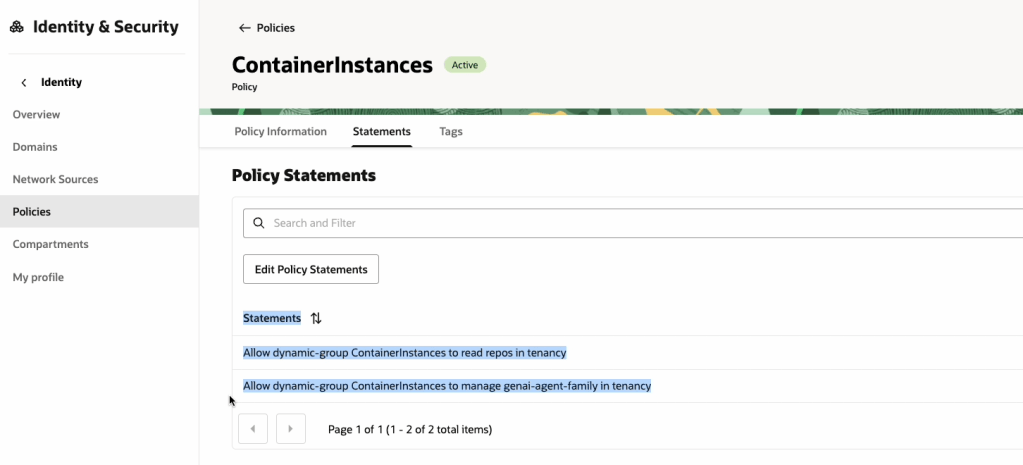
The policy should have the following two statements:
Allow dynamic-group ContainerInstances to read repos in tenancy
Allow dynamic-group ContainerInstances to manage genai-agent-family in tenancy
Now that we’ve got the Dynamic Group and Policy created, we can move on to Step 2!
Step 2 – Obtain an auth token and get the tenancy namespace ✅
An auth token is required to authenticate to the OCI Container Registry service, which is required when pushing the container image to the registry.
To create an Auth Token, do the following:
Make sure that you copy the Auth Token somewhere safe as you will not be able to re-retrieve it after creation ⛔️.
We now need to get the tenancy namespace, which is required to authenticate to the Container Registry, this can be obtained as follows:
Now onto Step 3 👇
Step 3 – Create a Container Image of the Streamlit App ✅
The code that I will use for the Streamlit App can be found on GitHub, this is a basic app that connects to an OCI Generative AI Agent and allows a user to ask the agent questions:
Once you have this, two additional files are required to create the container image:
requirements.txt, which should contain the following and includes the Python packages required to run the Streamlit app:
streamlit
oci
…and Dockerfile (no file extension required!), which is used to create the container image. This will launch the Streamlit app listening on port 80. Ensure that you update the name of the Python script (in this case OCI-GenAI-Agent-Streamlit.py) to reflect the name of the script you need to run.
Place the requirement.txt, Dockerfile and Python script into a single directory:
…and then zip this up.
Now login to the OCI Console, launch Cloud Shell, upload the zip file and uncompress (this is a quick way to transfer the files).
We can now create the container image and upload this to the container registry, to do this run the following commands – make sure you run these from the directory that has been un-zipped, which contains the Streamlit app.
You may also need to update lhr.ocir.io to the correct endpoint for the container registry in your tenancies region, a full list of endpoints can be found here.
It will then prompt for your password, for this you will need to enter the Auth Token 🎫 obtained in Step 2 (you did save this, right?)
Here’s a short run-through of this:
Next step is to build the container image and upload this to the container registry, you will need to run the following commands to do this.
Make sure that you update the endpoint (lhr.ocir.io) if needed and namespace (lrdkvqz1i7e6). This command will build the container image and tag it with the name streamlit:latest – this command needs to be run from the un-zipped directory that contains the Streamlit app files.
Once it has built, it can be pushed to the OCI Container Registry using the following command:
Step 4 – Create a container instance from the container image ✅
We are nearly there 🏁, the final step is to create a container instance from the container image that we have just pushed to the container registry.
To do this, you’ll need a Virtual Cloud Network (VCN) that has a public subnet (so that we can make the instance available over the Internet 🌍), if you don’t have one, you can use the VCN Wizard to quickly do this, as documented here.
Make sure you have a Security List 📋 entry that permits access to the public subnet within the VCN on port 80 – in my case from any public IP address, but you may want to restrict this to specific public IP addresses.
Once you have confirmed that you have a VCN in place, we can go through the process of creating the container instance using the container image that we just created.
I’ve used the default settings for creating a container instance, in the real-world, you’d need to select an appropriate compute shape (CPU/memory).
Grab the public IP address assigned to the container instance and open this in your browser of choice, the Streamlit app should open (all being well!).
You may want to create a DNS entry and point this towards the public IP, to make it easier to access.
Also in my final disclaimer, for anything but quick and dirty demo’s you should run this over SSL with authentication too! An OCI Load Balancer can be used to do SSL termination and Streamlit provide a useful guide on performing authentication, which can be found here.
I attended a security focussed hackathon with two of my immensely talented colleagues recently (James Patrick and Hussnan Haider) 🧠.
One of the challenges we ran into when configuring identity federation between OCI and a separate trusted identity provider (such as Microsoft Entra ID or Okta), is that users had to perform MFA twice – once for the trusted identity provider and then for OCI IAM, this is obviously not ideal for users, it was super frustrating for us 😫!
I’ve put together a short video that runs through the solution we put together to ensure that MFA within OCI IAM is bypassed when a separate federated identity provider is used for authentication 📼.
Key thing to point out here, is that the federated identity platform will be wholly responsible for MFA in this case, therefore it’s critical that this has been configured so that users require MFA for authentication, otherwise you have users authenticating to OCI using a single factor, which is not good 📱!
For further background on how to configure identity federation between OCI IAM and Microsoft Entra ID/Azure AD, check out my two previous posts on this topic.
OCI Generative AI Agents recently released the ability to query a database using natural language (similar to Select AI), more details on this new feature can be found here.
In this short video, I walkthrough the end to end process of creating an OCI Generative AI Agent and configuring this to query a database using natural language.
I’ve been building a lot of OCI Generative AI Agents for customer demos recently 🤖, one demo that typically resonates well with customers is a RAG agent that uses text scraped from their public website, for example when working with a council this can demonstrate how residents can use a Generative AI Agent to quickly get answers to their questions about council services…….without the hassle of navigating their maze of a website 👩💻.
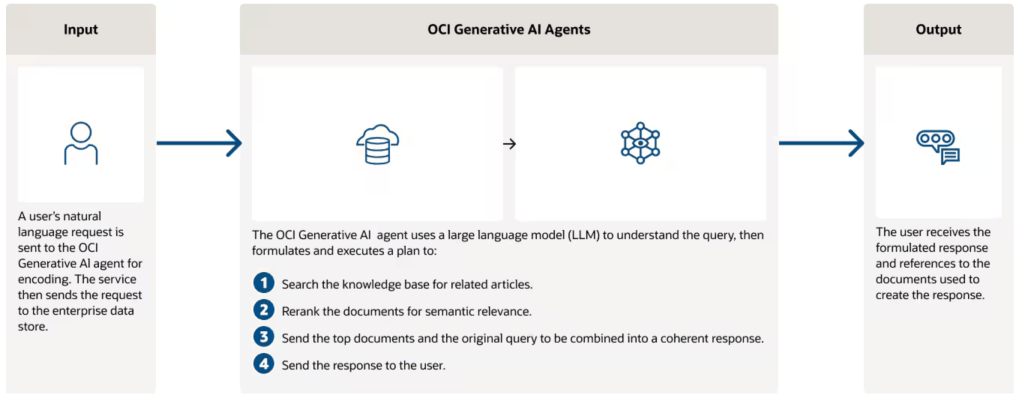
For reference here’s how an OCI Gen AI Agent works at a high-level.
In the real world a Gen AI Agent would use internal data that isn’t publicly accessible, however I typically don’t have access to customers data, therefore the approach of crawling their public website works well to showcase the capabilities of a Gen AI Agent and begin a conversation on real-world use-cases that use internal data 📊.
I wrote a very hacky Python script to crawl a site and dump the content to a text file which can then be ingested into a Gen AI Agent…….however this is super unreliable as the script is held together with sticking plasters 🩹 and constantly needs to be updated to work around issues experienced when crawling.
I recently stumbled across a fantastic Python package named Trafilatura which can reliably and easily scrape a site, enabling me to retire my hacky Python script 🐍.
Trafilatura can be installed using the instructions here (basically pip install trafilatura).
Once it had been installed, I was able to scrape my own blog (which you are currently reading) using two commands!
The first command grabs the sitemap for https://brendg.co.uk, and writes a list of all URLs found to URL.txt.
The second command takes the URL.txt file as input and for each URL within, crawls the page and writes the contents to a text file within the folder txtfiles.
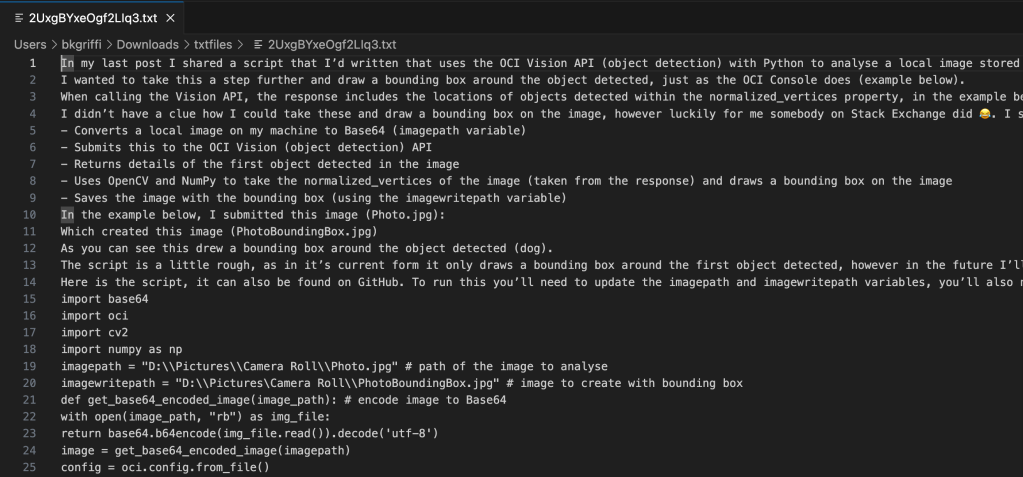
Below is an example of one of the text files that have been output, you can clearly see the text from the blog post scraped.
Such a useful tool, which will save me a ton of time ⏱️!
I’ve been working on a project deploying an OCI Generative AI Agent 🤖, which I’ve previously spoken about here 📼.
Marketing blurb – OCI Generative AI Agents is a fully managed service that combines the power of large language models (LLMs) with AI technologies to create intelligent virtual agents that can provide personalized, context-aware, and highly engaging customer experiences.
When creating a Knowledge Base for the agent to use, the only file types that are supported (at present) are PDF and text files. I had a customer that needed to add Word documents (DOCX format) to the agent, rather than converting these manually which would have taken a lifetime 🕣, I whipped up a Python script that uses the docx2pdf package – https://pypi.org/project/docx2pdf/ to perform a batch conversion of DOCX files to PDF, one thing to note is that the machine that runs the script needs Word installing locally.
Here is the script 👇
import os
import docx2pdf # install using "pip install docx2pdf" prior to running the script
os.chdir("/Users/bkgriffi/Downloads") # the directory that contains the folders for the source (DOCX) and destination (PDF) files
def convert_docx_to_pdf(docx_folder, pdf_folder): # function that performs the conversion
for filename in os.listdir(docx_folder):
if filename.endswith(".docx"):
docx_path = os.path.join(docx_folder, filename)
pdf_filename = filename[:-5] + ".pdf"
pdf_path = os.path.join(pdf_folder, pdf_filename)
try:
docx2pdf.convert(docx_path, pdf_path)
print(f"Converted: {filename} to {pdf_filename}")
except Exception as e:
print(f"Error converting {filename}: {e}")
convert_docx_to_pdf("DOCX-Folder", "PDF-Folder") # calling the function, with a source folder named DOCX-Folder and a destination folder named PDF-Folder, these folders should reside in the directory specified in line 4
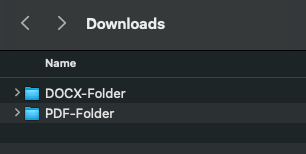
Folder structure 🗂️
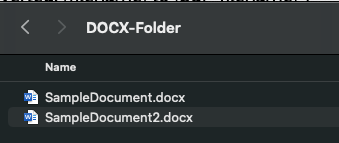
Source DOCX files 📄
Script Running 🏃
Output PDF files
Once the documents have been converted to PDF format they could be added to an OCI Storage Bucket and ingested into the OCI Generative AI Agent.