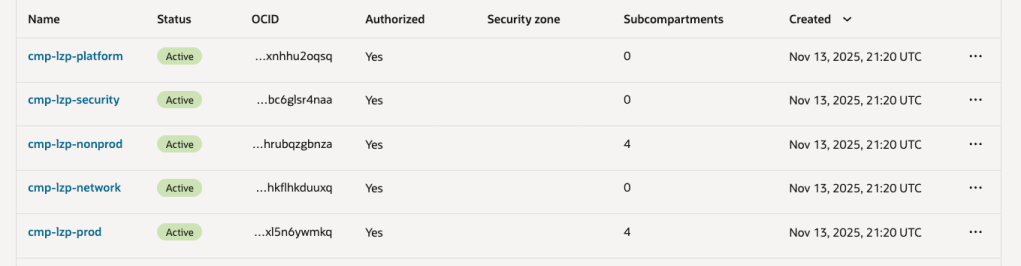
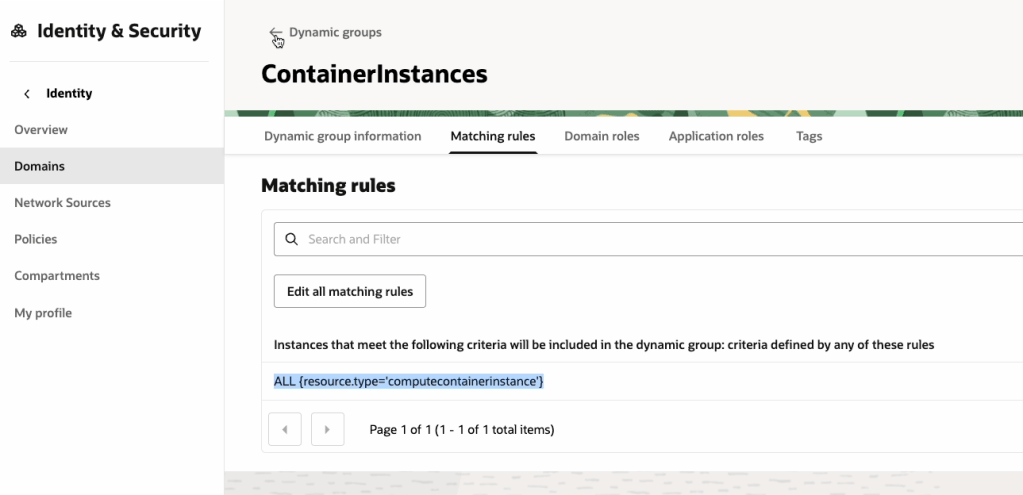
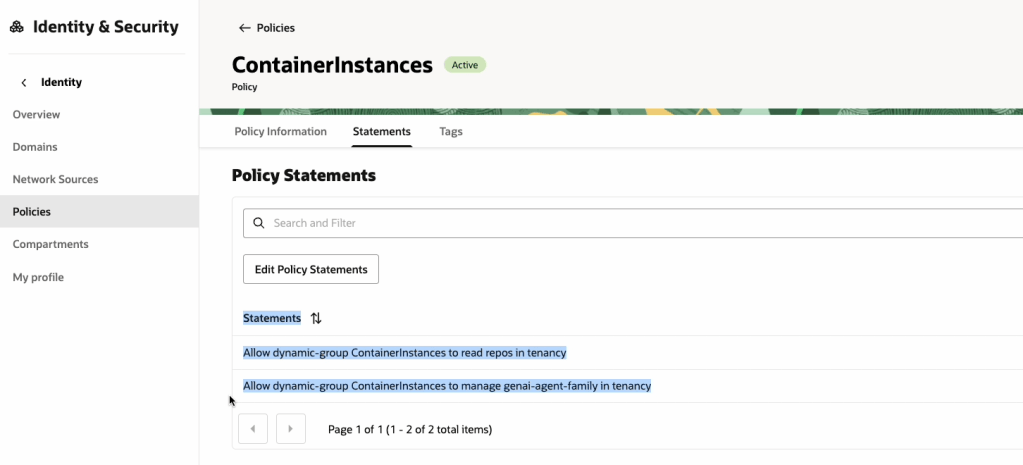
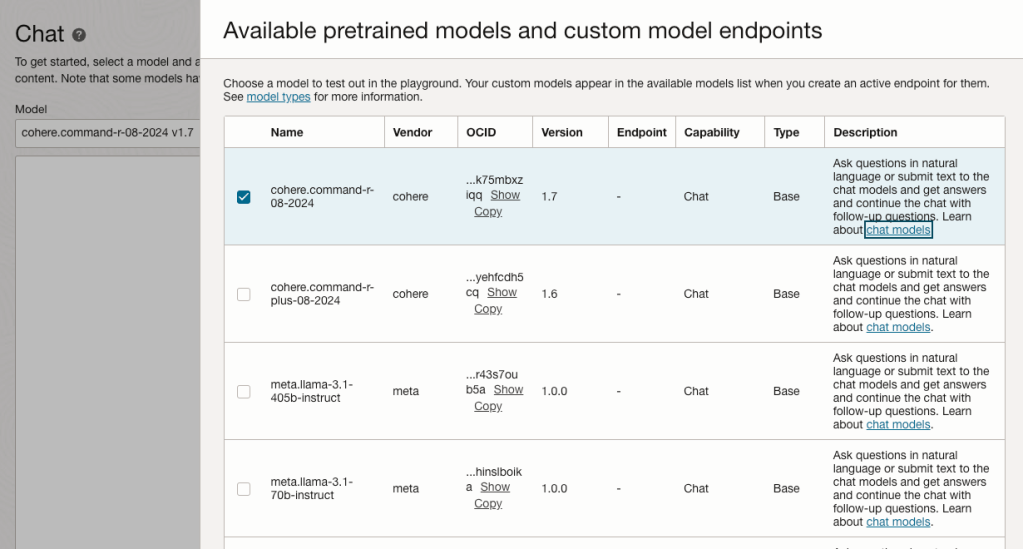
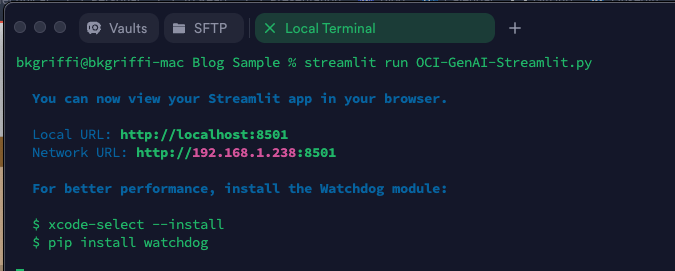
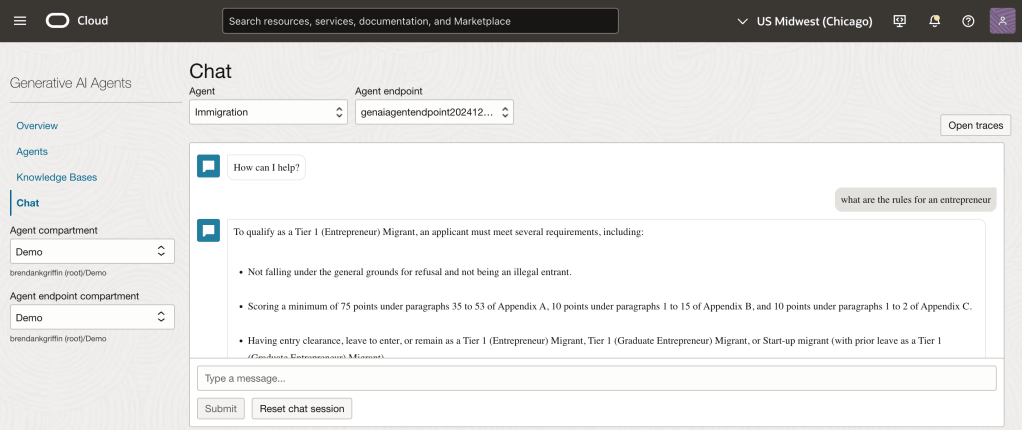
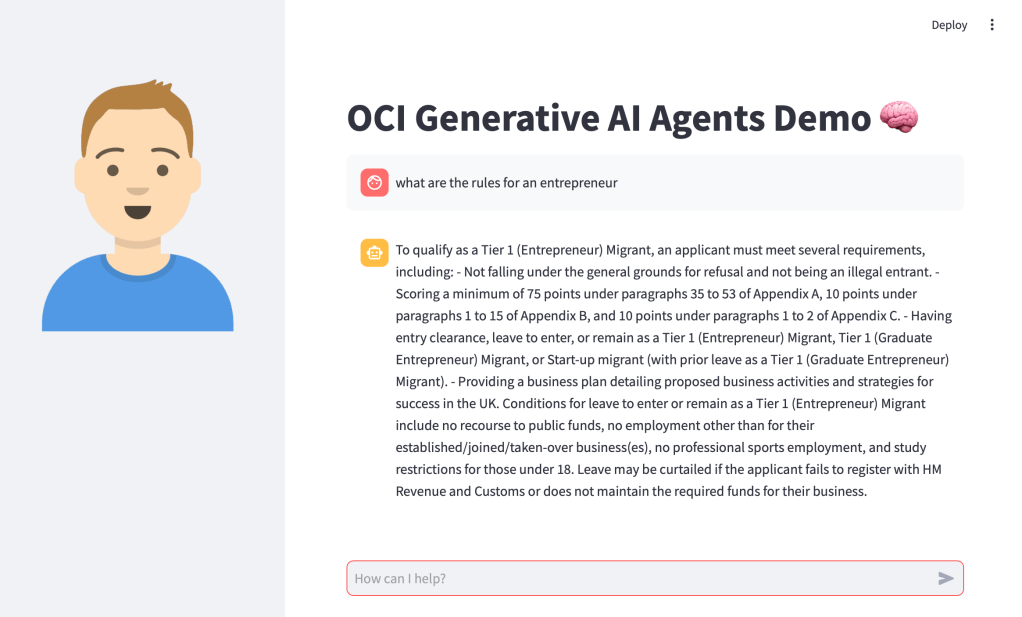
OCI has a number of Terraform based Landing Zone blueprints available.
The One OE (Operating Entity) OCI LZ blueprint can be deployed to an OCI tenancy directly from GitHub using the “Deploy to OCI” button:

This then uses OCI Resource Manager to deploy the blueprint to a tenancy – which uses Terraform under the hood.
I wanted to deploy the One OE blueprint to one of my test tenancies, however I wanted to do this natively using Terraform from my local machine rather than using OCI Resource Manager, mainly due to the additional flexibility and ease of troubleshooting that this approach provides.
It took me a while to figure out exactly how to do this (with a lot of help from one of the OCI LZ Black Belts 🥋).
I’ve documented the process that I followed below, hopefully it saves somebody else some time ⌚️.
✅ Step 0 – Make sure you have Terraform and Git installed (I’m assuming that you already have these installed locally).
✅ Step 1 – Create a directory to store the blueprints and configuration
I created a folder aptly named “OCI One OE Landing Zone“
…then opened a terminal and ran the following commands from within this folder:
git clone https://github.com/oci-landing-zones/oci-landing-zone-operating-entities.git
git clone https://github.com/oci-landing-zones/terraform-oci-modules-orchestrator.gitThese commands download the OCI OE Landing Zone blueprints and the Landing Zone Orchestrator.
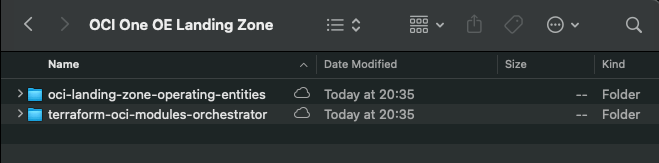
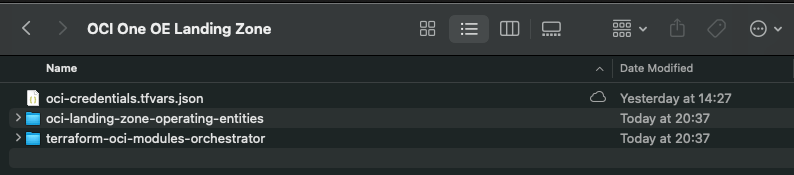
Once the downloads have completed, the folder should look something like this:
✅ Step 2 – Configure Authentication
Grab a copy of the file oci-credentials.tfvars.json.template, which is located within the folder OCI One OE Landing Zone/oci-landing-zone-operating-entities/commons/content.

Take a copy of this file, place it in the root of the OCI One OE Landing Zone folder that you just created and rename the file to oci-credentials.tfvars.json
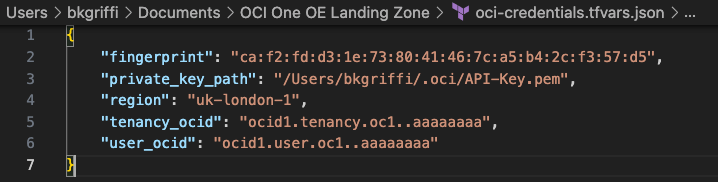
Open the oci-credentials.tfvars.json file and populate with your authentication information, if you don’t have this please follow the guide here to create an API Signing Key and obtain the other required information.
Here’s an example of what mine looks like:
✅ Step 3 – Grab a copy of the required configuration files
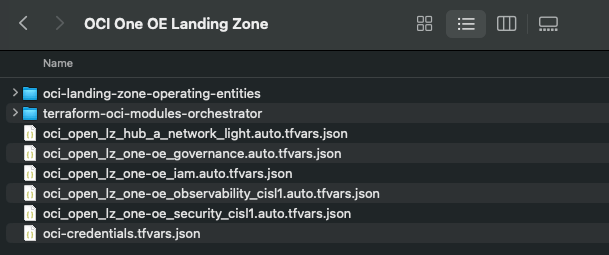
In order to deploy the One OE Landing Zone, a number of configuration files are required, these can be found within the following folder:
‘OCI One OE Landing Zone/oci-landing-zone-operating-entities/blueprints/one-oe/runtime/one-stack’
- oci_open_lz_one-oe_governance.auto.tfvars.json
- oci_open_lz_one-oe_iam.auto.tfvars.json
- oci_open_lz_one-oe_security_cisl1.auto.tfvars.json
- oci_open_lz_hub_a_network_light.auto.tfvars.js
- oci_open_lz_one-oe_observability_cisl1.auto.tfvars.json
Copy these files into the root of the OCI One OE Landing Zone folder – you can leave them in their original location, but by taking a copy this means that you can edit them (if needed) and easy return them to their “vanilla” state by re-copying across from their original location.
✅ Step 4 – Time to deploy 🚀
Run the following command from within the OCI One OE Landing Zone/terraform-oci-modules-orchestrator folder to download the required Terraform Providers and Modules
terraform initOnce this has completed, run terraform plan (from the same folder), referencing the required configuration files:
terraform plan \
-var-file ../oci-credentials.tfvars.json \
-var-file ../oci_open_lz_one-oe_governance.auto.tfvars.json \
-var-file ../oci_open_lz_one-oe_iam.auto.tfvars.json \
-var-file ../oci_open_lz_hub_a_network_light.auto.tfvars.json \
-var-file ../oci_open_lz_one-oe_security_cisl1.auto.tfvars.json \
-var-file ../oci_open_lz_one-oe_observability_cisl1.auto.tfvars.json ….if all goes well, you can run terraform apply (from the same folder) using the exact same configuration files.
terraform apply \
-var-file ../oci-credentials.tfvars.json \
-var-file ../oci_open_lz_one-oe_governance.auto.tfvars.json \
-var-file ../oci_open_lz_one-oe_iam.auto.tfvars.json \
-var-file ../oci_open_lz_hub_a_network_light.auto.tfvars.json \
-var-file ../oci_open_lz_one-oe_security_cisl1.auto.tfvars.json \
-var-file ../oci_open_lz_one-oe_observability_cisl1.auto.tfvars.json Within a few minutes, you should (hopefully!) have a beautiful OCI Landing Zone deployed within your tenancy.